CMU 15-721 Lecture 1 - Modern OLAP Database Systems
The History of OLAP
Problem: 隨著數據分析的需求上升,資料庫的使用者已經不再只單純透過 SQL 來查詢資料,而是需要更多的分析功能,最初多透過單體式的資料庫系統去滿足這些需求,讓資料庫管理這些原始資料、聚合資料如何被存放,然而隨著時間和需求變化,誕生了 OLAP (Online Analytical Processing) 為概念的資料庫系統逐漸設計出來。
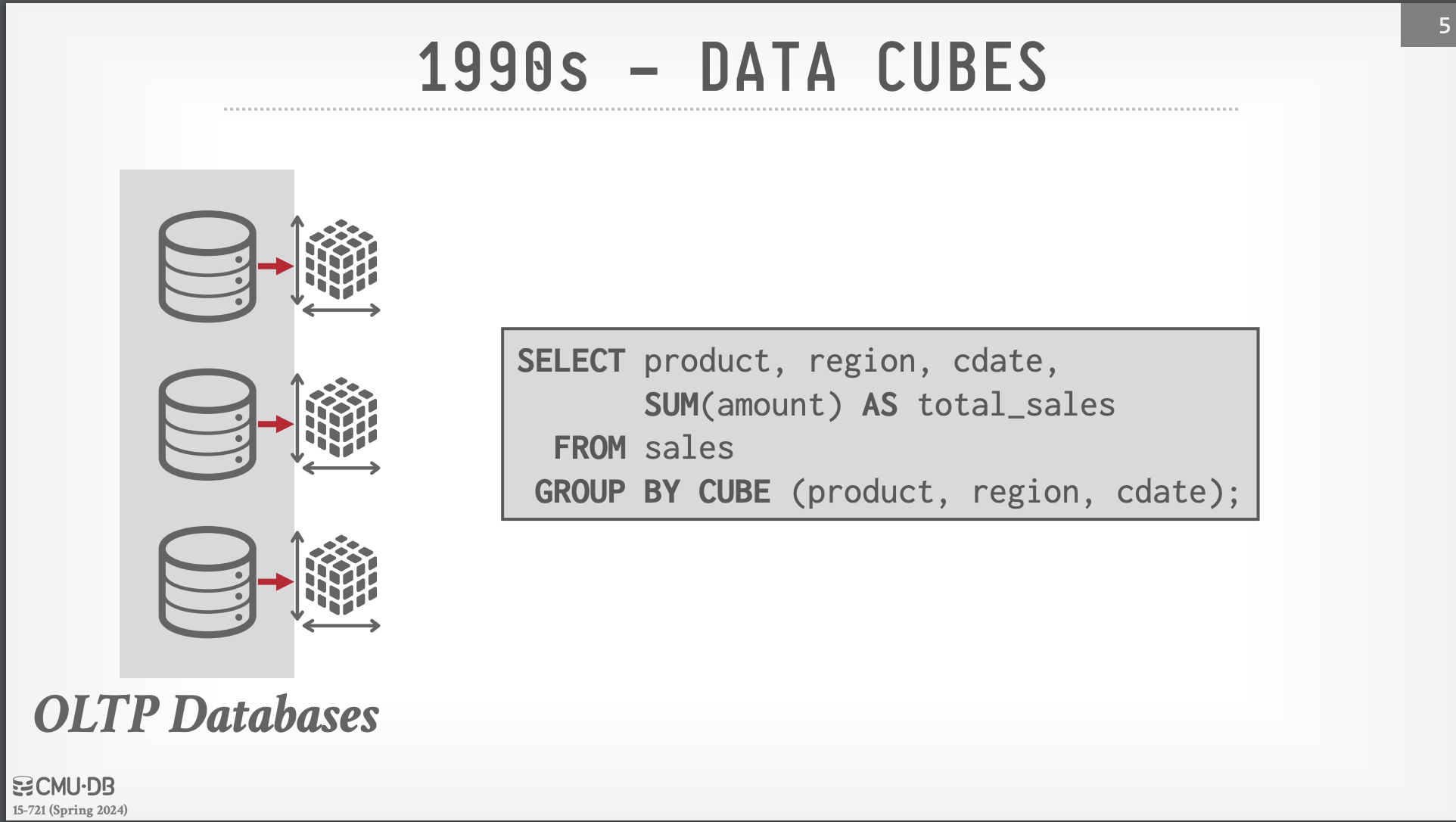
- 1990s: Data Cubes - 在當時時空背景下所提供的資料儲存格式多為存於硬碟的 row store,使用情境多為 transaction-based 運算邏輯,並不完全適合於分析需求。以分析的情境來說,對於 query 部分欄位的資料,資料庫不需要先將整個 row page 讀取出來,而是可以直接讀取部分欄位的資料。因此,Data Cubes 的概念被提出,將資料庫的資料預處理以多維度、聚合的 materialized view 的方式存放,但因為不容易透過 incremental 的方式維護,必須透過 預先定義並以 cronjob 形式更新這個 view,以提供了更多的分析功能,例如:roll-up, drill-down, slice, dice, pivot 等等。當時的 database system 如 Oracle, DB2, SQL Server 都有提供這樣的功能。
-
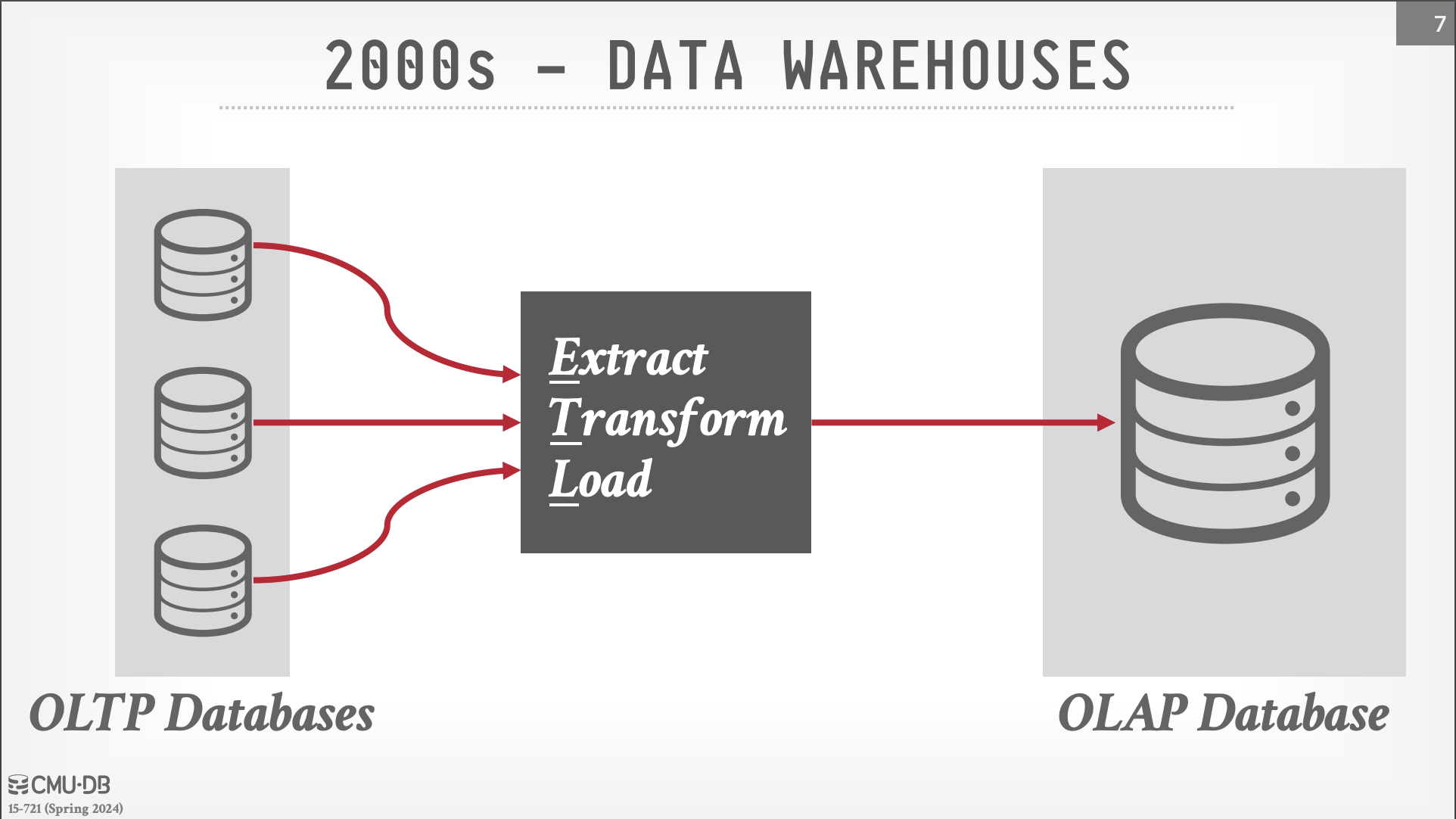
2000s: Data Warehouse - 2000 年代開始,人們開始建立分析導向的資料庫,當時多數系統 fork 自 postgres 並重新根據 columnar 資料存取的需求設計了系統內部存放格式及 running execution 的方式。
- 當時的 ParAccel 是 redshift 的前身,fork 自 PostgresDB 的 MonetDB 則是 DuckDB 的前身(MonetDB-lite)
這個時候依然是以單體資料庫方式去管理資料的存放格式及存放方式。而相較於後續的 OLAP 設計架構,此時的系統設計為 Share-Nothing System。此時系統的使用方式多為 OLTP database 透過 ETL/CDC 的方式將資料複製到 Data Warehouse,然而 Data Warehouse 的 Schema 和運算資源依然需要事先定義準備。
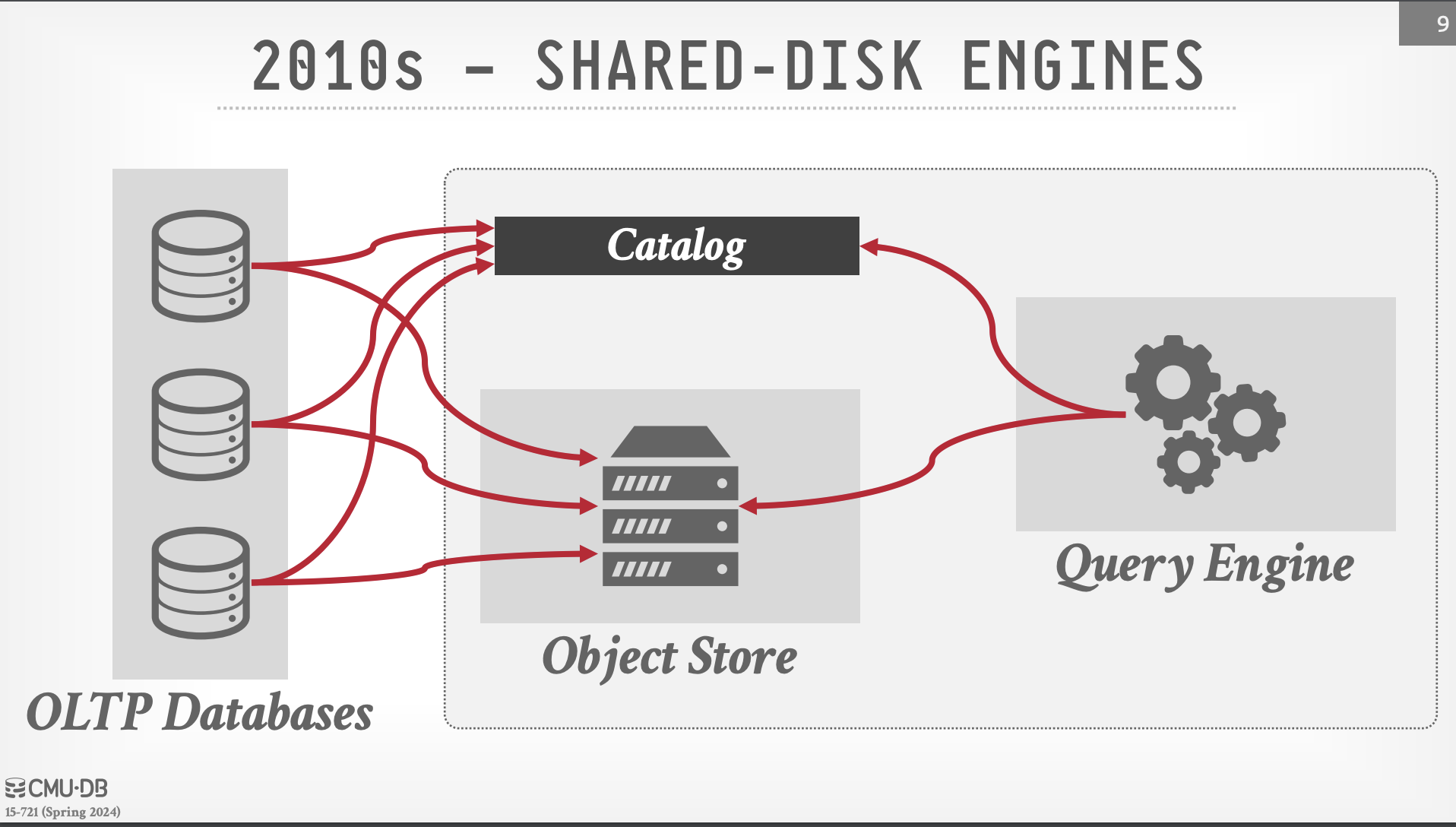
- 2010s: Share-Disks Engines: 隨著運算需求的上升,此時設計的 OLAP 系統將 Storage Layer 和 Computation 的職責分離,OLAP 資料庫不再直接管理資料的存放,取而代之透過 Cloud Object Store 去存放這些大型的物件,並且透過另外的 Catalog Service 去註冊這些物件的 metadata,以供 Computation Layer 去進行運算。這樣的設計讓 OLAP 資料庫可以更加容易擴展、設計運算導向的資料格式,並且可以透過分散的 computation instance 去進行運算。這樣的系統架構開始有 Lakehouse System 的雛形,意即 Data Lake + Data Warehouse 的結合。各式各樣的 OLAP 資料庫開始出現,Facebook 的 Presto 和衍生的 Trino, Google 的 BigQuery, AWS 的 Redshift, LinkedIn 的 pinot, 還有 Snowflake、Databricks 等等。此時系統的使用方式為 OLTP database 透過 ETL/CDC 的方式將資料寫入至 Object Store 並且於 Catalog Service 註冊這些資料,而 OLAP 資料庫實則作為 Query Engine 參考照 Catalog Service 的 Metadata 去取得這些資料並進行運算。
Andy Pavlo 提到 Data Lake 更像是一個 Marketing Term,其實質意義是指任何人可以將任何資料存放於公開的 Object Store 不必透過 DBA 或特定資料庫去存放資料,而 Data Lakehouse 是指將 Data Lake 和 Data Warehouse 的功能結合在一起,並且透過 Metadata Layer 來管理這些資料。
- 2020s: Lakehouse-System - Databricks 2021 年的 Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics 中提到自 2015 年後開始 data lake + data warehouse 的 two-tier 架構使得資料的不易管理並且有 Reliability、Data Staleness 的問題,因此在這個時期的系統開始提供 Reliable Data Management 的功能,透過 log-structured file 的方式進行資料的 schema/versioning 的 transaction CRUD 管理和追蹤並讓使用者確保可以在 Catalog 得到想要的資料版本。如 Netflix 的 Iceberg,Uber 的 Hudi,Databricks 的 Delta Lake 皆是此時期的產物。
Lakehouse System 的誕生得益於以下幾個情境:
- 使用者已不再只透過 SQL 進行資料查詢,而是需要更多的分析執行功能。
- 資料的存取和計算分離,使得資料交換和定義更加容易
- 資料的需求不再只是結構化資料,而是半結構化和非結構化資料。
OLAP DBMS Components
從 Monolithic Database 到 Lakehouse System,OLAP System 的架構逐漸拆分為多個獨立的服務,並且透過相互間的溝通和協作來完成 OLAP 的功能。這些 Component 主要分為:
- System Catalog
- Intermediate Representation
- Query Optimizer
- File Format/ Access Libraries
- Execution Engines/ Fabrics
Architecture Overview
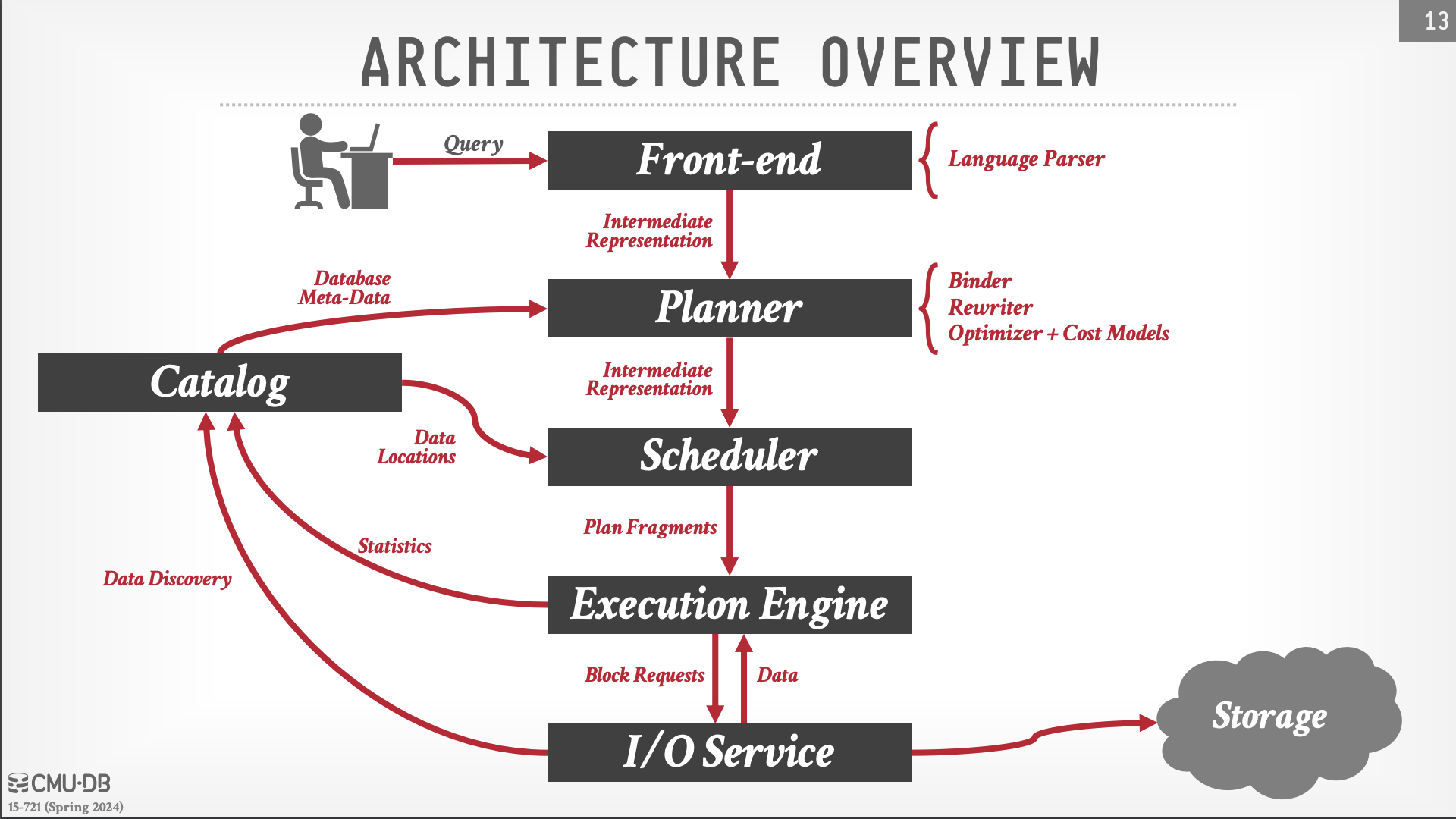
- User -> Frontend: 使用者透過 Frontend 進行 Query 的發送
- Language Parser: Convert SQL to Intermediate Representation (Tokens)
- Frontend -> Planner: Frontend 將 Query 轉換成 Tokens 後送至 Planner 並產出 Pyhsical Plan
- Binder: Catalog 會提供 Planner 所需的 Metadata,而 Binder 會綁定 tokens 到對應的存在的 table
- Rewriter: rewrite the query to optimize the query
- Optimizer: generate the query plan based on cost model and statistics
-
Scheduler: 將以 IR 表示的 Query Plan 參考 Catalog 提供的 Data Location 去 dispatch Query Plan 到對應 cluster 的 Execution Engine
-
Execution Engine: 根據 Query Plan 分散處理執行 Query 並且將結果回傳給 User
- Execution Engine -> I/O Service: 由於需要從 Data Layer 取得資料,因此 Execution Engine 會像 I/O Service 發送 Request 並且取得資料,I/O Service 會根據 Catalog 提供的 Metadata 去 Storage 取得資料
Snowflake 的 Catalog 使用 FoundationDB 來存放 Metadata,以保證 ACID、高容錯、高效能的特性
延伸問題
-
為什麼將選擇將資料存放於 Cloud Object Store?與直接存放於硬碟有什麼 trade-off?
將 Storage Layer 和 Computation Layer 分離的好處是所有的存放不再唯有透過資料庫才可以存放,任何人都可以直接存放在 Cloud Object Store 並決定是否進一步被 OLAP 資料庫所使用,而存放格式也不不再局限於資料庫的設計和預先定義的 Schema 更貼合 semi-structure 資料的需求。 -
Catalog 在 OLAP System 中扮演相當重要的角色,如何避面 Single-Point-of-Failure 的問題?
See Also
References
- S2024 #01 - Modern OLAP Database Systems (CMU Advanced Database Systems)
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics